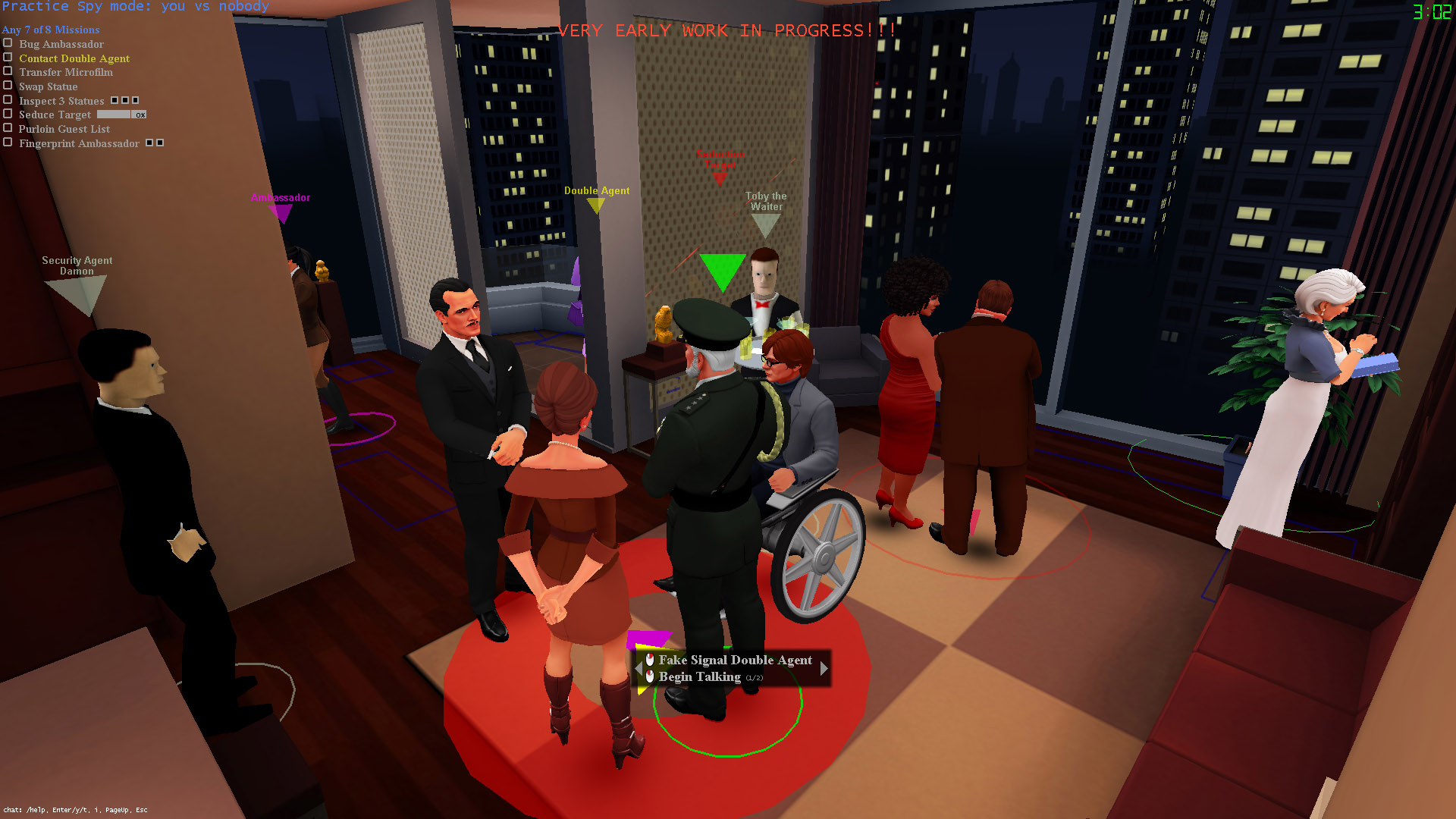
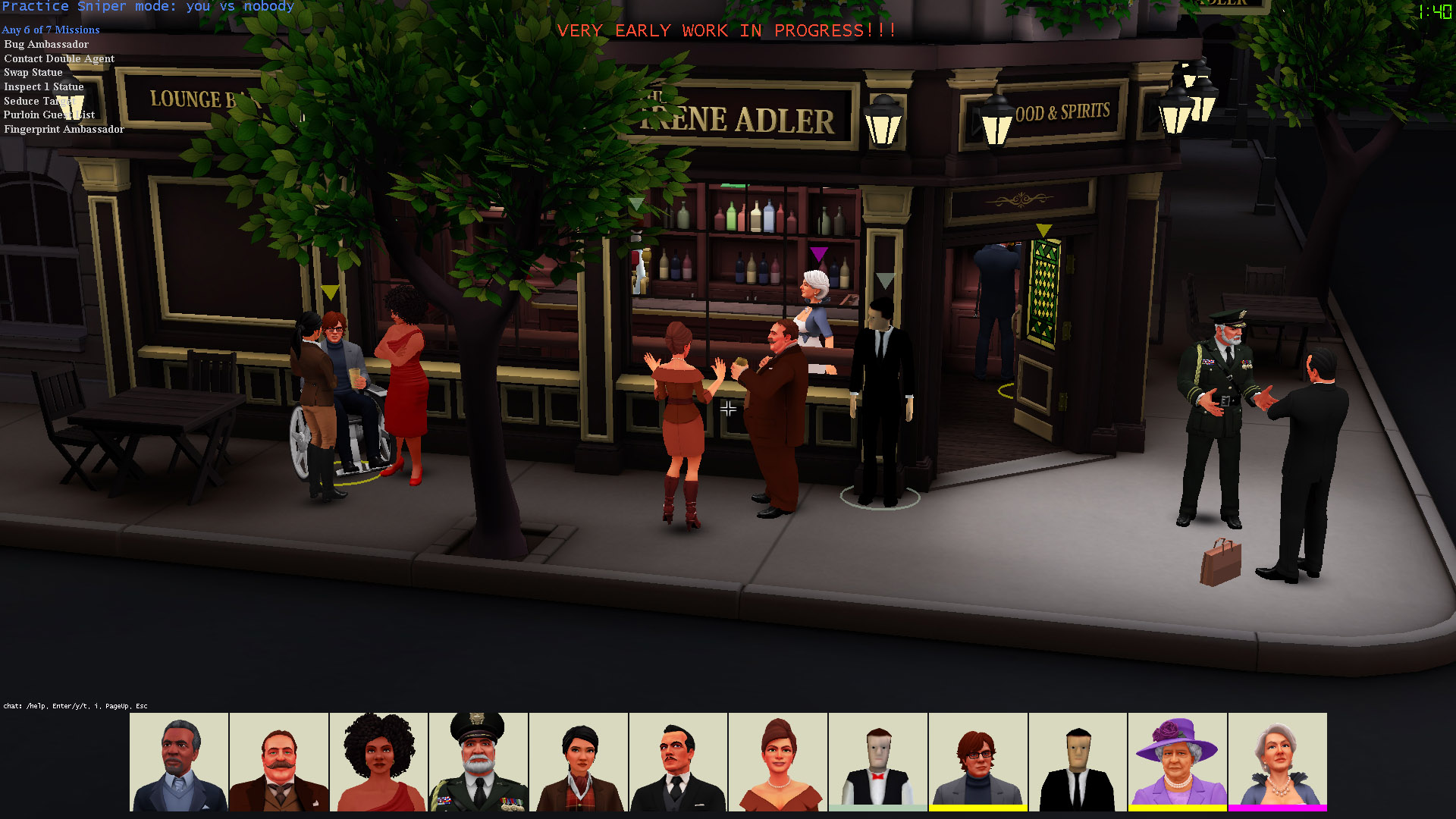
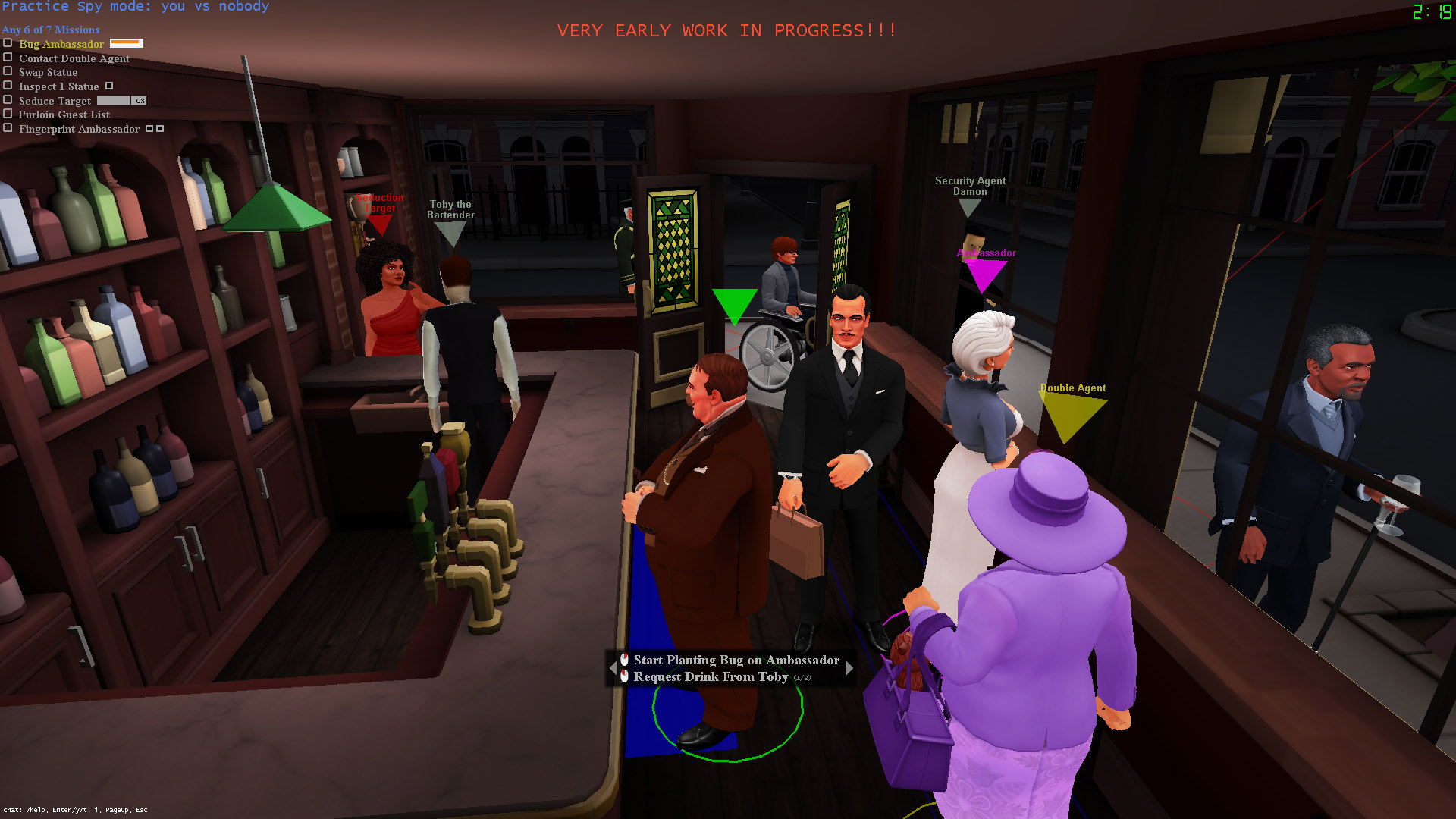
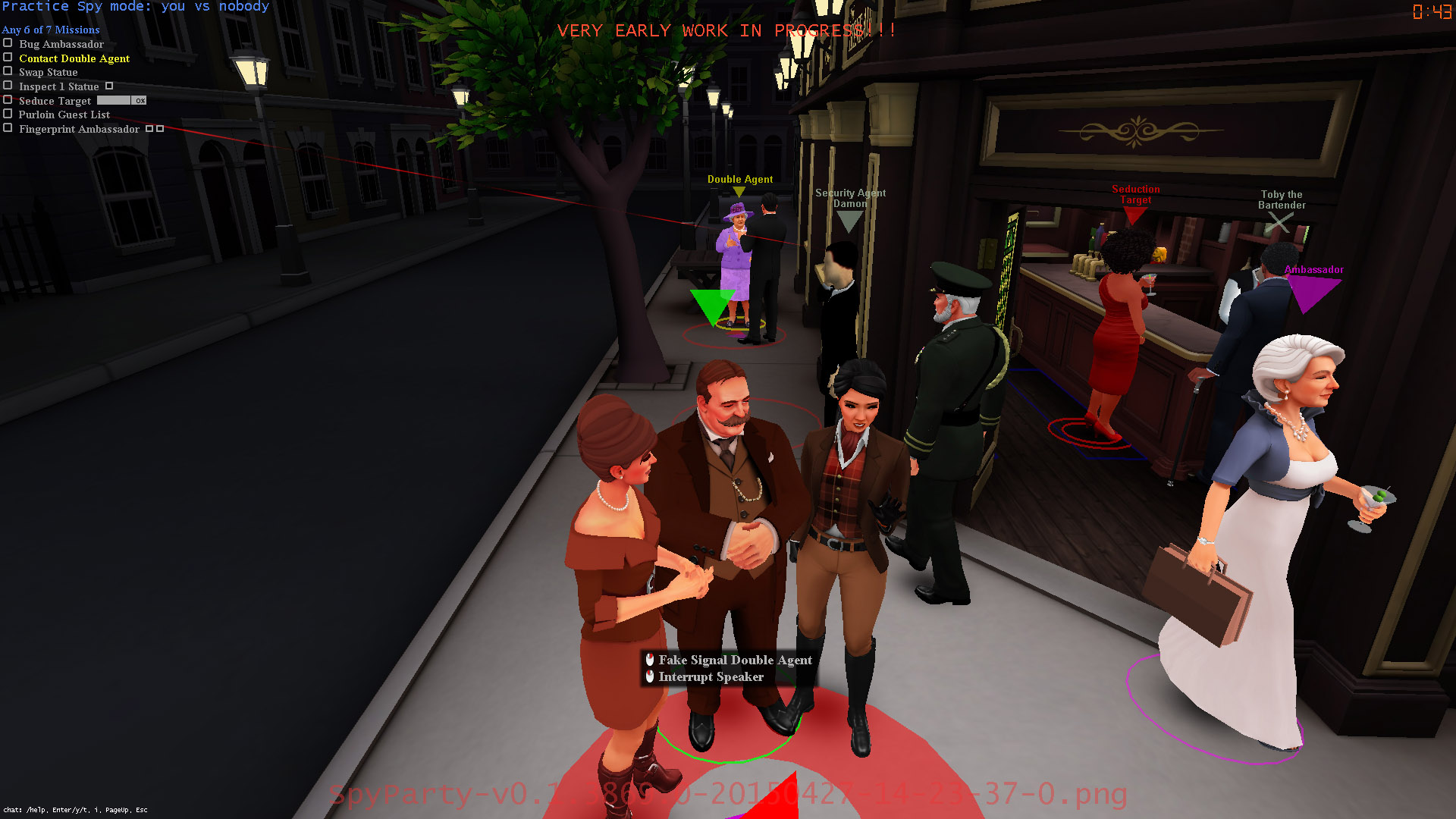
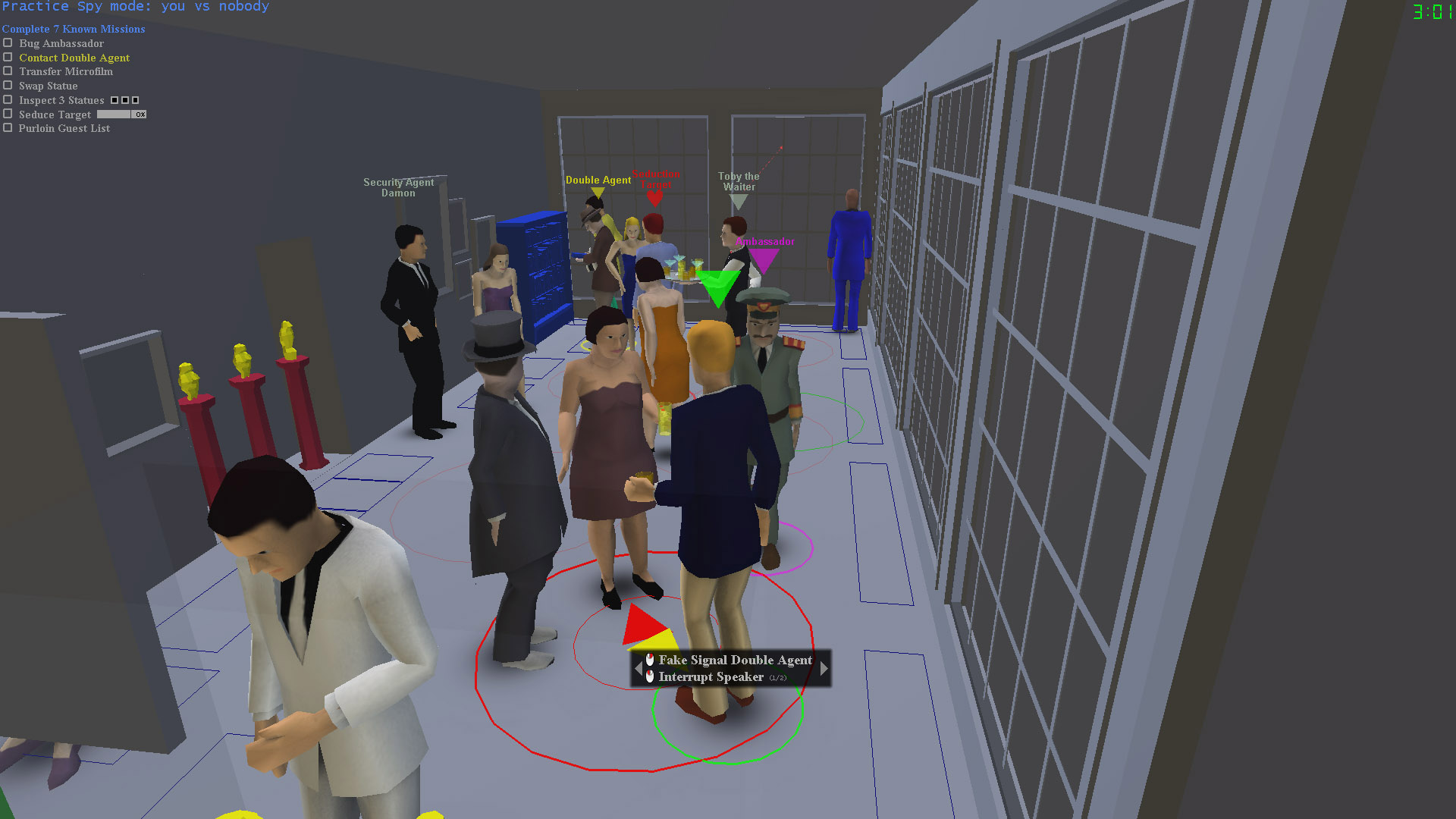
SpyParty is a tense competitive spy game set at a high society party. It's about subtle behavior, perception, and deception, instead of guns, car chases, and explosions. One player is the Spy, trying to accomplish missions while blending into the crowd. The other player is the Sniper, who has one bullet with which to find and terminate the Spy!
SpyParty is in Early-Access Beta right now, which means you can buy and play the game immediately, you'll get all the updates during development, and then you'll get the final version when it ships. The beta community is friendly and welcomes new players, and there's a private beta forum where players share strategies.
As you can see from these screenshots, we're in the process of replacing the older prototype art with shiny new art. You can see more of the new art here and here.